Tutoriel : accès et utilisation des clusters de calculs.
Posted on Thu 14 May 2020 in tutoriels • 7 min read
Pourquoi ce tutoriel ?
Une lecture attentive de ce tutoriel vous permettra de commencer à utiliser les clusters de calcul disponibles au LJK. Vous y trouverez les étapes classiques (connexion, lancement de calculs) et quelques exemples d’utilisation. Pour une utilisation avancée, la lecture de la documentation de GRICAD reste indispensable.
Pré-requis
- Quelques bases en commandes linux.
Pour se former
Voir par exemple ce cours que nous donnons au collège doctoral, les bases du système Linux pour le calcul scientifique
- La lecture du Descriptif des ressources en calcul
- La lecture du glossaire HPC
Etapes
Dans ce tuto, nous répondrons aux deux questions suivantes
-
Comment aller sur les clusters ?
-
Accès aux clusters : comment configurer sa connexion (ssh)
-
Comment travailler sur les clusters ?
Travailler sur un cluster implique de le partager avec de nombreux autres utilisateurs, ayant tous des besoins différents (d’un point de vue logiciel). L’environnement par défaut est minimal, il est impossible de mettre en place un environnement logiciel qui convienne à tous.
Par conséquent, vous aurez besoin :
-
d’un outil de partage des ressources (noeuds, coeurs …), pour planifier vos jobs. C’est le rôle du “batch scheduler” OAR,
-
d’un outil pour construire votre environnement logiciel et ses dépendances. Il faudra choisir parmi guix, nix, singularity …
-
Accès au service : Perseus
Pour utiliser les clusters de calcul il est nécessaire :
- d’être enregistré dans le système d’information de GRICAD, Perseus,
- d’être membre d’un projet déclaré via cette même interface.
Warning
- Seuls les membres permanents ont le droit de créer des projets
- Lors de votre inscription, renseignez correctement le champ “LAB” en précisant bien LJK.
Pour plus de détails, nous vous invitons fortement à lire cette page : https://gricad-doc.univ-grenoble-alpes.fr/services/
Accès aux clusters
Le chemin vers les clusters est représenté sur le schéma ci-dessous :
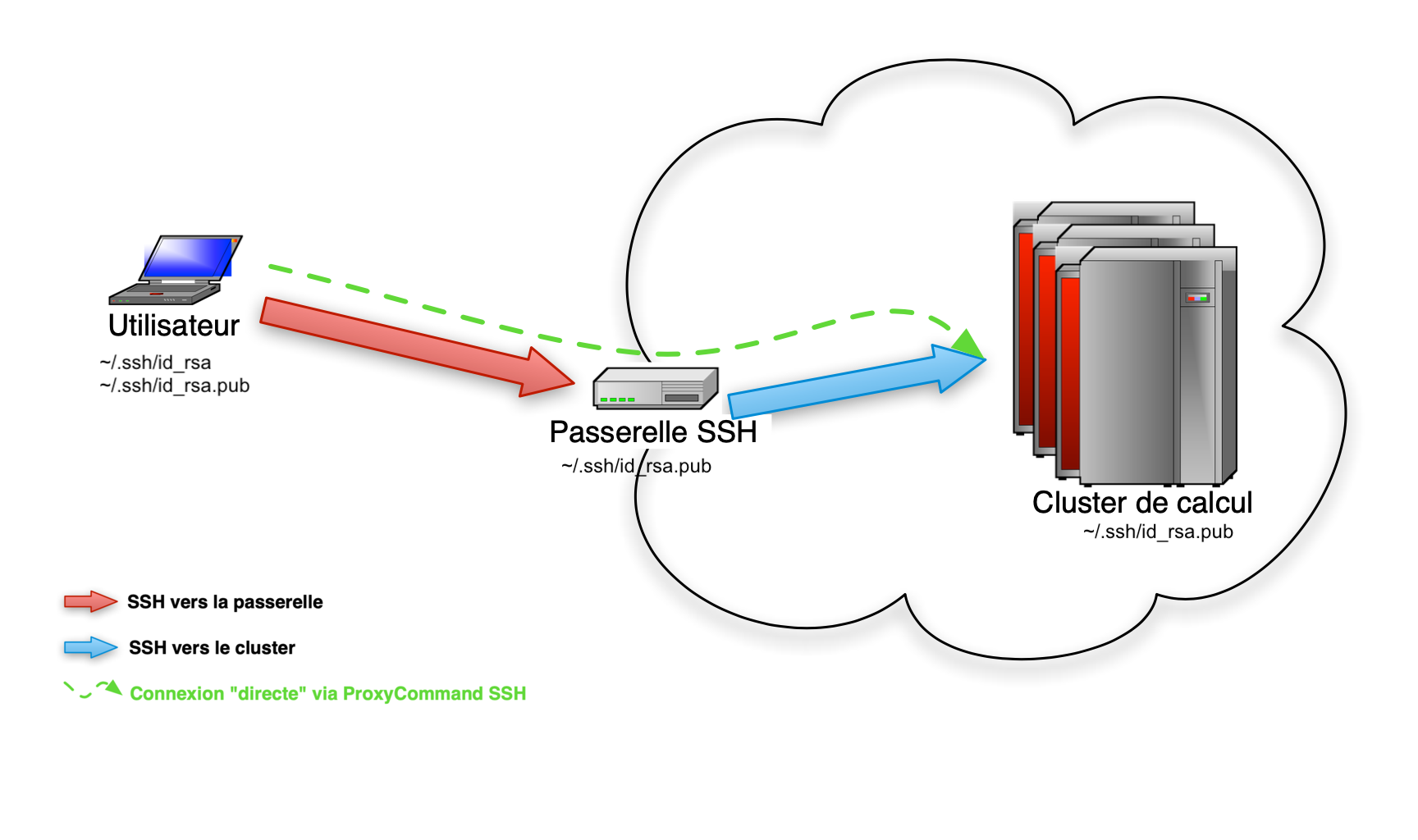
Votre objectif est maintenant de pouvoir faire sur votre machine personnelle
monlogin@mamachine$ ssh luke.gricad
pour accèder directement sur la frontale d’un cluster (Luke dans le cas présent).
Pour cela, il faudra :
- générer une paire de clé SSH.
- configurer les ProxyCommand SSH (en langage courant : éviter le rebond sur la passerelle)
- distribuer votre clé publique aux machines sur lesquelles vous voulez vous connecter
Tip
Si vous êtes pressé, voici un résumé des commandes à exécuter, mais nous vous recommandons quand même de suivre le détail des étapes décrites ci-après.
Générer une paire de clés SSH
Attention
Cette étape n’est nécessaire que si vous ne possédez pas déja un jeu de clés !
Vérifiez le contenu du répertoire .ssh/.
monlogin@mamachine$ cd
monlogin@mamachine$ ls .ssh/
id_rsa id_rsa.pub
Si il contient deux fichiers id_rsa et id_rsa.pub vous pouvez passer à l’étape suivante.
Dans le cas contraire, il faut générer des clés :
monlogin@mamachine$ ssh-keygen -t rsa
Répondez simplement aux questions en laissant les valeurs par défaut, sauf si vous savez ce que vous faites.
Ayez bien en tête que lors de la création des votre paire de clés, vous devez fournir une passphrase non vide, ce qui doit normalement être plus long qu’un mot de passe.
Dans tous les cas, faites attention lorsque vous essayez de vous authentifier. Lorsque vous vous identifiez avec :
- vos identifiants Perseus : on vous demandera votre password
- votre paire de clés SSH : le système vous demandera votre passphrase.
Après cette étape, deux fichiers ont été générés :
.ssh/id_rsa: votre clé privée et strictement personnelle.ssh/id_rsa.pub: la clé publique correspondante à votre clé privée.
Configurer le ProxyCommand SSH
Ou “comment automatiser le rebond sur la passerelle ?”.
Pour cela, il faut créer ou ajouter ces lignes à un fichier .ssh/config dans votre répertoire personnel.
# Connexion aux machines GRICAD
Host *.gricad
User votre_login_perseus
ProxyCommand ssh -q <votre_login_perseus>@access-gricad.univ-grenoble-alpes.fr "nc -w 60 `basename %h .gricad` %p"
ForwardAgent yes
Pour les utilisateurs Mac OS, il est recommandé d’ajouter ces lignes à la fin du fichier .ssh/config.
Host *
UseKeychain yes
AddKeysToAgent yes
SendEnv LANG LC_*
Distribuer votre clé publique
Distribuer tout d’abord votre clé publique sur la passerelle.
Depuis votre machine faites :
monlogin@mamachine$ ssh-copy-id mon_login_perseus@rotule.u-ga.fr
# ou / et
monlogin@mamachine$ ssh-copy-id mon_login_perseus@trinity.u-ga.fr
Comme indiqué plus haut, le système vous demande ici votre password Perseus.
Vérifier ensuite que cette étape fonctionne (toujours depuis votre machine):
monlogin@mamachine$ ssh mon_login_perseus@access-gricad.univ-grenoble-alpes.fr
A cette étape, le système vous demande la passphrase de votre paire de clés SSH.
Vous devriez maintenant être connecté sur la passerelle (regarder le prompt pour vous assurer de cela).
Si tout c’est bien passé, vous pouvez maintenant copier votre clé plublique sur la frontale de chaque cluster auquel vous souhaitez acceder (Luke, Dahu, Bigfoot). (Pensez à vous déconnecter de la passerelle avant de poursuivre)
monlogin@mamachine$ ssh-copy-id dahu.gricad
Selon votre configuration locale, vous allez devoir fournir votre passphrase 2 fois pour vous connecter successivement sur la passerelle puis sur la frontale du cluster.
Pour éviter ce phénomène, nous vous encourageons à utiliser un agent SSH (sur votre système) qui mémorisera votre passphrase pendant la durée de votre session sur votre ordinateur.
Félicitations ! Vous êtes connecté sur le cluster. Si ce n’est pas le cas, n’hésitez pas à prendre contact avec nous.
Pour aller plus loin…
Pour de plus amples informations, vous pouvez vous reporter aux documentations suivantes :
- https://pole-calcul-formation.gricad-pages.univ-grenoble-alpes.fr/ced/unix/
- Les pages 2-4 de ces slides : https://pole-calcul-formation.gricad-pages.univ-grenoble-alpes.fr/ced/pdf/consignes.pdf
- Comment se connecter : https://gricad-doc.univ-grenoble-alpes.fr/hpc/connexion/
Composer mon environnement :
Vous avez un projet Perseus, vous êtes capable de vous connecter sur un cluster, mais sur la frontale, il est peu probable que vous trouviez les logiciels dont vous avez besoin. En effet, les clusters étant partagés par de nombreux utilisateurs, il n’existe pas d’environnement magique qui convienne à tout le monde. Vous devrez donc le construire et l’adapter à vos besoins.
Comment ?
Plusieurs options s’offrent à vous : nix, guix, conda, modules, singularity …
Que choisir ?
Il n’y a pas d’outil miracle, tout dépendra des logiciels dont vous aurez besoin.
Bonne pratique
Nous vous recommandons de nous lister les softs nécessaires pour que nous puissions vous aiguiller vers le gestionnaire d’environnement le plus adapté à votre besoin.
Dans le doute, nous vous conseillons d’opter pour guix, qui, de notre point de vue, est le plus simple et le plus fonctionnel.
Guix express
Pour un apreçu rapide de l’utilisation de GUIX, consultez la Guix cheatsheet.
Voici quelques cas d’usage classiques :
- Python, avec quelques package classiques (numpy, …)
- R,
- Compilateur C/C++, Fortran
- GPUs
- Julia
Pour aller plus loin :
Réserver des ressources et lancer ses codes
Pour lancer un calcul, il faut passer par OAR (gestionnaire de batch) pour réserver des ressources et/ou planifier le lancement de votre calcul.
La documentation complète est disponible sur le site de Gricad.
Pour une rapide revue des utilisations classiques de oar, consultez l’aide-mémoire
Voici deux scénari standards et un résumé des quelques commandes qui vous permettront de démarrer sereinement.
Tuto 1 : mode Interactif, pour le prototypage et les tests.
Objectif
Exécuter R sur un noeud de calcul, en interactif.
Méthode
Depuis la frontale d’un cluster (luke dans cet exemple) :
monlogin@luke$ oarsub -I --project=Mon_projet -l /nodes=1/core=2,walltime=02:00:00
[ADMISSION RULE] Modify resource description with type constraints
[PROJECT] Adding project constraints: (team='ljk' or team='ciment' or team='visu')
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=39620730
Interactive mode: waiting...
Connect to OAR job 39620730 via the node luke38
- -I comme interactif
- \(-\ell\) nodes=X/core=Y à lire de droite à gauche : signifie “je veux Y coeurs par noeud sur X noeud”.
- Toujours préciser le nom du projet
- Durée par défaut : 2h
Voila ! Vous êtes connecté sur luke38 et en mesure de lancer vos calculs :
monlogin@luke38$ source /applis/site/guix-start.sh
monlogin@luke38$ R
R version 4.0.0 (2020-04-24) -- "Arbor Day"
Copyright (C) 2020 The R Foundation for Statistical Computing
...
Puis quand vous avez terminé, il suffit de libérer les ressources en quittant le noeud
monlogin@luke38$ exit
logout
Connection to luke38 closed.
Disconnected from OAR job 39620730.
et vous voila de retour sur la frontale.
Vous auriez pu également demander un noeud précis, luke42 par exemple :
monlogin@luke$ oarsub -I --project=siconos -p "network_address='luke42'" -l /nodes=1/core=2
[ADMISSION RULE] Set default walltime to 7200.
[ADMISSION RULE] Modify resource description with type constraints
[PROJECT] Adding project constraints: (team='ljk' or team='ciment' or team='visu')
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=39621434
Interactive mode: waiting...
[2020-07-07 15:34:22] Start prediction: 2020-07-07 15:34:22 (R=2,W=2:0:0,J=I,P=siconos (Karma=0.000,quota_ok))
Starting...
Connect to OAR job 39621434 via the node luke42
Tuto 2 : mode Batch, pour lancer des calculs plus conséquents.
Le mode interactif est pratique pour de petits calcul, du debug, des tests mais insuffisant et peu pratique pour des calculs longs. Nous allons maintenant voir comment décrire et enregistrer un job dans une file d’attente.
Objectif
Soumettre un job en mode batch sur le cluster
dahu.
Méthode
Sur la frontale du cluster dahu :
- descrire vos besoins (ressources, commandes à lancer) dans un script
- soumission : le job passe dans la file d’attente et sera exécuté quand les ressources seront disponibles.
Le script monscript.sh
#!/bin/bash
# -- Un nom pour le job --
#OAR -n MonJob
# -- Description des ressources souhaitées --
#OAR -l /nodes=1/core=3,walltime=00:01:30
# -- Et bien sur, le projet Perseus --
#OAR --project test
# -- Puis la liste des commandes à exécuter --
source /applis/site/guix-start.sh
cd /bettik/$USER/
/bin/ls >> test.txt
source /applis/site/guix-start.sh
python -c 'print("hello")'
Warning
- Les lignes commençant par #OAR ne sont pas des commentaires !
- Le script doit être executable
A faire lors de la création du fichier :
monlogin@f-dahu$ chmod + x monscript.sh
Tout est prêt, il ne reste plus qu’a placer notre job dans la file d’attente :
monlogin@f-dahu$ oarsub -S ./monscript.sh
[ADMISSION RULE] Modify resource description with type constraints
[PROJECT] Adding project constraints: (team='ljk' or team='ciment' or team='visu')
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=39623764
Suite à cette commande, vous restez sur la frontale et votre job est en attente. Deux premiers réflexes :
- utilisez la commande oarstat pour suivre votre job (voir Suivre un job)
- vérifiez la présence des deux fichiers suivants :
monlogin@f-dahu$ ls
OAR.MonJob.39623764.stderr
OAR.MonJob.39623764.stdout
Le premier contient une capture de la sortie erreur (vide si tout va bien) et le second la sortie standard de vos calculs.
monlogin@f-dahu$ less OAR.MonJob.39623764.stdout
hello
Autres pointeurs utiles
-
La documentation officielle de Gricad : https://gricad-doc.univ-grenoble-alpes.fr/hpc/
-
Les cours du collège doctoral : https://pole-calcul-formation.gricad-pages.univ-grenoble-alpes.fr/ced/
voir le module “outils de développement” pour tout ce qui touche à la compilation, à gitlab etc
Résumé : une séquence de calcul “standard”
En résumé, lancer un calcul sur le cluster doit correspondre plus ou moins à la séquence suivante :
- Connection sur une frontale.
- Préparation de l’environnement de travail (guix …).
- Ecriture d’un script oarscript.sh.
- Oarsub -S ./oarscript.sh.
- Vérification du fichier OAR….stderr.
- Suivi du job (oarstat, htop, monitoring oar, …).
- Attendre …
- Récupération des résultats dans /bettik/$USER ou ailleurs.
- Nettoyage ! Suppression de tous les fichiers dont vous n’avez plus besoin.
Warning
Ne négligez pas cette dernière étape et prenez le temps de nettoyer vos espaces sur le disque.